Last December I wrote a post about building a bespoke commenting for Jekyll. I had been using Jekyll for a couple of months at the time, and not having an easy solution for a commenting system was the first big limitation of a static site I had to deal with. I didn’t want to use a third-party service, like Disqus, so I decided to build a bespoke solution because I knew what I wanted — or I thought I did.
To sum it up, I used Poole to handle and store my comments data and then built a server-side middleman that would get the feed from Poole, convert the Markdown to HTML and return the comments in pure HTML, ready to be appended to the page. A bit of JavaScript would then make the call to this middleman on every post and append all the comments to the page.
The beauty in our industry is that to keep afloat you need to be constantly learning and rethinking your processes and principles, and sometimes that means realising that the way you’ve done something in the past is not the best and that there are better and more elegant ways of going about things. I thought I knew what I wanted when I wrote that post, but I actually didn’t.
¶ What I got wrong
The main reason I didn’t want to go with something like Disqus was because it’s completely off-brand. My site is my property and the way it looks and feels throughout is part of my identity, so I didn’t want to introduce a third-party service that would interfere with that. Also, Disqus comes with a bunch of features I was simply not interested in, since I was after a very simple commenting system. I still very much stand by that idea.
However, it wasn’t until I watched a talk by Tom Preston-Werner at JekyllConf that I realised the bigger problem with platforms like Disqus and even with my own solution: where's the data? The beauty of building a site with Jekyll is that content is treated as part of the site and therefore hosted and versioned alongside the codebase, taking away the hassle of backing up and migrating databases and reducing the chances of content being lost.
With my Poole solution, where are my comments actually stored? What happens if the service suddenly disappears? The comments are important feedback to the subjects I write about and are as valuable as the posts themselves (or sometimes even more), so shouldn’t I be storing them in my repository along with every other component of the site? Also, relying on JavaScript to inject the comments on the page after it's served doesn’t really feel right.
This leaves us with an inevitable challenge: how can we take user input and add it to the static pages we serve? Isn’t that where we draw the line of when a dynamic site is required?
¶ The new plan
Another thing that I got wrong in my original post was saying that having to regenerate the site based on user input defeats the purpose of a static site. My reasoning behind it was that generating a site is expensive, both in terms of time and amount of operations that need to take place (e.g. push files to GitHub or run a deploy script). But actually, does that really matter? That operation will run in the background and will have no impact whatsoever on the user's experience. When the site finishes regenerating, the existing HTML pages are replaced by a set of new ones, and everything is again ready for the next visitor.
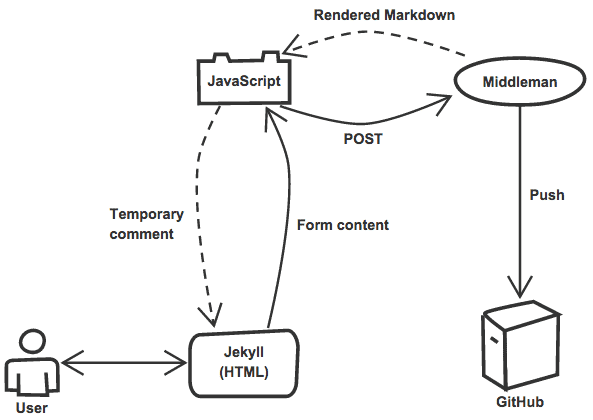
With that said, the new plan was to store each comment as a separate file in my _data directory, within a sub-directory for each post. To add a new comment, a server-side handler (or middleman) would receive a POST request with the form data, create a YAML file with the comment’s data and push it to GitHub, triggering a regeneration of the site.
On the front-end, JavaScript would hijack the form submission to avoid a page reload, sending the data as an asynchronous POST request via Ajax and preventing the default behaviour of a page reload. Upon confirmation of success, it would then append a temporary version of the new comment to the page, giving the feeling that the content was added instantly even though a lot of stuff still has to happen behind the curtain.
The form itself would have four fields: name (mandatory), email (mandatory, but not public), url (optional) and message (mandatory). My plan for the email address was to use it as a unique identifier for the user and also to attempt to pull an avatar from Gravatar, so I just needed it to create a md5 hash — I was not going to make it public for privacy and spammy reasons.
Finally, my middleman is a combination of a PHP/Slim script to handle the requests and a Bash script to create the files and push them to Git. A t1.micro free instance on AWS is hosting the middleman, while GitHub pages is hosting the Jekyll installation. Before going any further, please note that everything described in this post is a proof of concept and should not be used on production as is!
¶ Part 1: The bash script
Let’s start from the end of the process and create the bash script that will take the comment data, create a YAML file and push it to GitHub. My idea was to create an independent file, completely decoupled from the PHP script, so it can potentially be used in the future by other entities or components.
The script will take 5 arguments: the post slug (e.g. 2015-05-11-rethinking-the-commenting-system-for-my-jekyll-site), the date and time of the comment, the commenter’s name, email address MD5 hash and url, and finally the message. I'll skip the part where the arguments are filtered and assigned to variables because it's just boilerplate code, but they will eventually end up in the variables POST_SLUG, DATE, NAME, EMAIL_HASH, URL and MESSAGE.
We’ll use a config file to store general settings to be used by both the Bash script and the PHP handler. We'll store things like the GitHub user and repository details (where GIT_REPO is the path for the local folder and GIT_REPO_REMOTE is the remote location) and folder structure to be used for the comment files. In this example, each comment will be in a YAML file named {date-and-time}-{email-hash}.yml (e.g. 20150510170537-b7284abf8c22bf9ba22069899511404c.yml), inside a directory with the post slug, all inside _data/. Here’s how my config file looks like:
GIT_USERNAME="eduardoboucas"GIT_REPO="/var/www/eduardoboucas.github.io"GIT_REMO_REMOTE="eduardoboucas/eduardoboucas.github.io.git"GIT_USER="Eduardo Boucas"GIT_EMAIL="mail@eduardoboucas.com"COMMENTS_DIR_FORMAT="_data/comments/@post-slug"COMMENTS_FILE_FORMAT="@timestamp-@hash.yml"We also need some sort of authentication to be able to push things to GitHub. Instead of using my password, which I want to keep safe from prying eyes, I generated a personal access token on GitHub and wrote it to a hidden file, called .gittoken, inside the repository — make sure to add that file to the .gitignore, because we don’t want to accidentally commit that file!
So when the script fires, we extract the arguments into variables, create a folder for the post if it doesn’t exist yet, and form the YAML file with the content from the comment.
# Read GitHub tokenTOKEN=`cat .gittoken`# Read config filesource configFILE="name: \"${NAME}\"\ndate: \"${DATE}\"\nhash: ${EMAIL_HASH}\n"if [ ! -z "$URL" ]; then FILE=${FILE}"url: \"${URL}\"\n"fiFILE=${FILE}"message: \"${MESSAGE}\"\n"# Change directory to repocd ${GIT_REPO}# Form comment file directoryCOMMENTS_DIR=${COMMENTS_DIR_FORMAT//@post-slug/$POST_SLUG}# Create directory if does not existif [ ! -d "$COMMENTS_DIR" ]; then mkdir ${COMMENTS_DIR}fiCOMMENT_TIMESTAMP=`date +%Y%m%d%H%M%S`COMMENT_FILE=${COMMENTS_FILE_FORMAT//@timestamp/$COMMENT_TIMESTAMP}COMMENT_FILE=${COMMENTS_DIR}/${COMMENT_FILE//@hash/$EMAIL_HASH}# Abort if file already existsif [ -f $COMMENT_FILE ]; then exit 0fi# Create fileprintf "$FILE" > $COMMENT_FILE# Prepare Git and commit fileGIT_ORIGIN="https://${GIT_USERNAME}:${TOKEN}@github.com/${GIT_REPO_REMOTE}"git config user.name ${GIT_USER}git config user.email ${GIT_EMAIL}git pull ${GIT_ORIGIN} mastergit add ${COMMENT_FILE}git commit -m "New comment (Jekyll Discuss)"git push --quiet ${GIT_ORIGIN} master > /dev/null 2>&1¶ Part 2: The PHP handler
With the bash script ready, we need something that triggers it from an HTTP request — in my case, a PHP script. All it needs to do is some very basic validation on the data received from the POST request, make sure that all the mandatory fields were filled in, check that the honey pot field was not, and then run the bash script we previously built using exec().
Finally, it runs the comment through a Markdown parser and echoes back the HTML result, along with the email hash, as JSON format. On the front-end, we'll use that data to generate a preview of the comment without forcing a page reload.
<?php// (Autoloading dependencies and initialising Slim...)$app->post('/comments', function () use ($app) { $data = $app->request()->post(); // Checking for the honey pot if ((isset($data['company'])) && (!empty($data['company']))) { return; } // Checking for mandatory fields if ((!isset($data['name'])) || (!isset($data['email'])) || (!isset($data['message'])) || (!isset($data['post']))) { echo('Mandatory fields are missing.'); return; } $date = date('M d, Y, g:i a'); // Create email hash $emailHash = md5(trim(strtolower($data['email']))); // Parse markdown $message = Parsedown::instance() ->setMarkupEscaped(true) ->setUrlsLinked(false) ->text($data['message']); $shellCommand = './new-comment.sh'; $shellCommand .= ' --name ' . escapeshellarg($data['name']); $shellCommand .= ' --date ' . escapeshellarg($date); $shellCommand .= ' --hash \'' . $emailHash . '\''; $shellCommand .= ' --post ' . escapeshellarg($data['post']); $shellCommand .= ' --message ' . escapeshellarg($message); if (isset($data['url'])) { $shellCommand .= ' --url ' . escapeshellarg($data['url']); } exec($shellCommand, $output); $response['hash'] = $emailHash; $response['date'] = $date; $response['message'] = $message; echo(json_encode($response));});?>¶ Part 3: Showing comments
With our server-side infrastructure taken care of, we're back to Jekyll. Since the comments are stored as flat files within _data/, it's pretty simple to access them. I started by creating an include file that will receive the comment data as arguments and print a single comment. I'll explain why in a second.
<article id="comment{{ include.index }}" class="comment"> <img class="comment__avatar" src="https://www.gravatar.com/avatar/{{ include.hash }}?d=mm&s=180" /> <h3 class="comment__author"> {% if (include.url) and (include.url != '@url') %} <a rel="nofollow" href="{{ include.url }}">{{ include.name }}</a> {% else %} {{ include.name }} {% endif %} </h3> <p class="comment__date"> {% if include.index %}<a href="#comment{{ include.index }}">#</a> {% endif %} {% if include.date %}{{ include.date }}{% endif %} </p> {{ include.message }}</article>I wanted to use Gravatar to display avatars for users that have one, which can be done with a simple GET request to gravatar.com with the email address hash (more info here). The {{ include.index }} field is used to create attach an ID to the comment so it can be navigated to directly using an anchor link.
Then I created an include file that will load all the comments for a given post.
<!-- _includes/blog/comments.html --><section class="comments"> {% capture post_slug %}{{ page.date | date: "%Y-%m-%d" }}-{{ page.title | slugify }}{% endcapture %} <hr class="comments__separator" /> <h2 class="comments__title">Comments</h2> {% if site.data.comments[post_slug] %} {% assign comments = site.data.comments[post_slug] | sort %} {% for comment in comments %} {% assign hash = comment[1].hash %} {% assign name = comment[1].name %} {% assign url = comment[1].url %} {% assign date = comment[1].date %} {% assign message = comment[1].message %} {% include blog/comment.html index=forloop.index hash=hash name=name url=url date=date message=message %} {% endfor %} {% endif %} <p class="comments__description">Leave a comment</p> {% include blog/newComment.html %}</section><script type="text/template" id="template--new-comment"> {% include blog/comment.html hash="@hash" name="@name" url="@url" date="@date" message="@message" %}</script>So what's happening here? Well, we capture the post slug to post_slug and use it to navigate through the data structure to get to the comments for that post. When that happens, we call the include file we previously created for each comment, passing the arguments extracted from the data file (line 18). But then we write that same file to the page inside a <script> tag, so it can be picked up as a template by our JavaScript and append a comment to the page. We pass some placeholders to it which later will be replaced by proper content.
¶ Part 4: Adding new comments
The form used to add new comments is inside newComment.html, which we included previously in our comments section (line 24). It's a very simple form and it's posting to the PHP handler on my AWS instance.
<!-- _includes/blog/newComment.html --><form id="comments-form" class="comments__new" action="https://aws1.bouc.as/jekyll-discuss/comments" method="post"> <input type="hidden" name="post" value="{{ post_slug }}" /> <input type="text" name="company" class="honey" /> <input type="text" name="name" placeholder="Name" required /> <input type="email" name="email" placeholder="Email address (will not be public)" required /> <input type="url" name="url" placeholder="Website (optional)" /> <textarea rows="10" name="message" placeholder="Comment" required></textarea> <span >You can use <a href="http://daringfireball.net/projects/markdown/syntax">Markdown</a> in your comment.</span > <input type="submit" value="Send" /></form>This would be enough to make everything work. The PHP handler could redirect users to the post they came from after it's finished, so they would basically just see a page refresh. The only problem with this approach is that because of the time it takes for the file to be pushed to GitHub and the site to be regenerated, the newly-added comment probably wouldn't yet be on the page when it reloads. That might be a bit confusing for the user, as they might think their comment wasn't succesfully added which could potentially lead them to submit it again.
A solution for this is to use JavaScript to stop a page reload and to append a fake copy of the comment to the page to let the user know that his content was submitted successfully. That temporary version of the comment will only be valid for the duration of his visit, since the next time they reload the page the site had hopefully been regenerated and they will see the permanent version of the comment.
So the first step is to prevent the default behaviour of the form submit and send the information via Ajax instead. Please note that since you'll be submitting the form to an external recipient, you'll need to enable CORS on the server or browsers will block the cross-domain Ajax request.
$("#comments-form").submit(function() { var url = $(this).attr("action"); var data = $(this).serialize(); var formName = $(this) .find('[name="name"]') .val() .trim(); var formUrl = $(this) .find('[name="url"]') .val() .trim(); var formEmail = $(this) .find('[name="email"]') .val() .trim(); $.ajax({ type: "POST", url: url, data: data, success: function(data) { var parsedData = JSON.parse(data); blog.addComment( parsedData.hash, parsedData.date, formName, formUrl, parsedData.message ); } }); return false;});Finally, we can create a function that creates a temporary comment and appends it to the page. I'm not using any client-side templating engine so I just used String.replace() to replace the placeholders with the real content, but if you are using one then it'll probably look nicer if you use it for this job.
addComment: function (hash, date, name, url, message) { var template = document.getElementById('template--new-comment').innerHTML; template = template.replace('@hash', hash) .replace('@date', date) .replace('@name', name) .replace('@message', message); if (url != '') { template = template.replace('@url', url); } $(template).insertBefore('.comments__new');},¶ Wrapping up
It's important to note that all this is just a proof of concept and this solution still needs some work before it becomes a reliable solution. The code for the server-side handler is on a GitHub repository, along with installation instructions. Everyone is more than welcome to add issues and pull requests.
Regenerating the site every time someone adds a comment may seem too radical for some people, but do think that's what the future of static site generators looks like. In his talk at JekyllConf, Parker Moore mentioned that future versions of Jekyll will be able to do a selective regeneration of a site, using an internal dependency management system to determine which files are affected by every change, allowing the engine to regenerate those files only and not the entire site.
Maybe that's a sign that this approach makes sense. Or maybe I'll write another post in a couple of months saying that I got it all wrong again. What are your thoughts? ∎
*Update 03/10/2016: I turned this concept into a service called Staticman. It's free and open-source and you can read more about it in this post.*