This article is part of a series called «Microservices and Node.js»:
- Introduction to microservices
- The principles of microservices
- Microservices vs. Service-Oriented Architecture
- Microservices: not a free lunch
- Microservices + Node.js
Designing software systems is hard. When I first mastered a programming language, I started to feel confident about writing code and even proud of how efficient, elegant and flexible I could make it. But little did I know that writing software is so much more than that.
As the size and complexity of the projects I worked on grew, I learned that a group of people is responsible for making decisions that have a much larger impact than the code written by any single individual. Software architects, as they’re usually known, are in charge of devising and outlining the bigger picture of a system, directly impacting (for better or worse) every single phase of the project’s lifecycle, from the development stage until long after its final release.
¶ System architecture
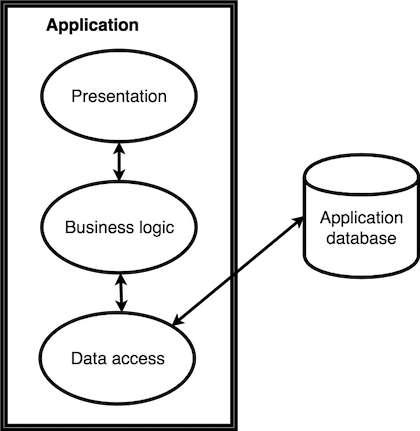
Over the years, software architects have been finding better mechanisms for designing systems that are scalable, maintainable and easy to reason about. The N-tier architecture is a famous example of that, introducing a separation of concerns that divides code into at least three layers: data management, business logic and presentation. Whilst good in principle, reality shows that it’s difficult to keep the presentation layer truly impermeable. Without a mechanism to detect when this principle is violated, business logic will eventually leak to the presentation layer, creating a tight coupling and a maintainability nightmare that are very difficult to backtrack from.
The hexagonal architecture is an evolution from that, introducing the concept of ports and adapters to enforce stricter encapsulation and stronger separation of concerns, encouraging developers to reason about their applications as a series of modular components rather than a stack of wide, heavy horizontal layers. But even then, we’re still looking at a large monolithic application that needs to be managed and deployed as a whole, limiting the ability to effectively commit a change to a single part of the system with the confidence that it won’t affect others.
In recent years, we’ve seen an increased interest in a fundamentally different paradigm called microservices, which is characterised by promoting components to self-contained, autonomous and independently deployable services. The core principles it introduces are seen as a robust and reliable way of building systems, and key players in the industry are using them in large-scale production products.
In this series of articles, we’ll dissect those principles through a balanced analysis of their promised benefits and the common pitfalls, finishing with a (somewhat opinionated) technical view on why microservices and Node.js are a match made in heaven.
¶ The monolith
In a traditional approach, we typically have a single application formed by a codebase internally divided into the following layers:
- A presentation layer used to display content to users, also potentially receiving input (in the case of a web application, this would be a set of HTML pages or templates);
- A data access layer that reads from and writes data to a database;
- A business logic layer responsible for all the processing in between, running logic that is specific to the organisation's business domain.
The various components that form each of these layers are then bundled together and deployed to a production server as a single, unitary entity.
Let’s imagine the system of a newspaper organisation built with this architecture, using a relational database as a data store. If we were to render a page with a particular news story along with all the user-generated comments associated with it, the application would query the Stories and Comments tables, using a SQL JOIN or similar, process and format the data as needed and display it back to the client. All this communication and processing happens using in-process calls, within the boundaries of a single application.
So what exactly are microservices and how do they differ from the monolithic paradigm? Whenever someone asks me that question or when I’m delivering a talk on the subject, I always refer to this quote from Martin Fowler:
The microservice architectural style is an approach to developing a single application as a suite of small services, each running in its own process and communicating with lightweight mechanisms, often an HTTP resource API. These services are built around business capabilities and independently deployable by fully automated deployment machinery.
With microservices, components don't live together inside the boundaries of a single unit. Instead, this architecture promotes the development and deployment of applications as a suite of independent, self-contained services. If we were to rebuild the example above using this architectural style, the steps we’d follow to obtain the same content could be quite different.
Instead of having the application querying a single database for stories and comments, we could have a Stories service solely responsible for storing, managing and delivering stories. The service would run on its own process and any communications to and from it are established via network calls, processed by its own web server and using an API that is exposed to the outside world. If the service itself needs to make use of other services, this also happens over network calls (with the exception of a connection to a database, which may or may not be a direct in-process call). The same principles can also be applied to a Comments service, as illustrated in Figure 1-2.
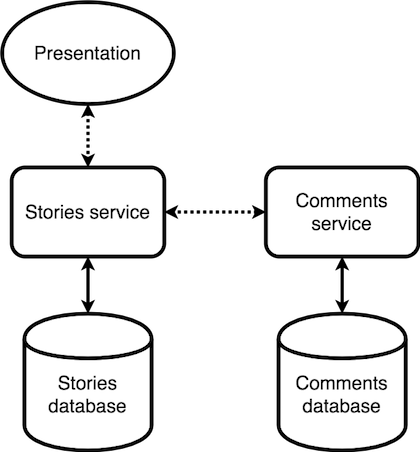
We know that microservices are about building a system through composing multiple independent services, but what else defines this architectural style? We’ll cover the key principles of microservices, and the associated benefits they can bring to a system and organisation, in the next article in the series. ∎
Next in the series: The principles of microservices